This is Day 2 of an 18-day series building an open-source EU banking data governance pipeline. The end product is a valid EBA XBRL COREP submission produced by a fully governed, independently restartable data pipeline using only open-source tools.
Yesterday I explained what data governance is and why banks treat it as a matter of survival. Today I want to go one level deeper: the specific regulations that create those governance obligations.
EU banking runs on acronyms. Walk into any regulatory reporting team and within five minutes you will hear CRR, CRD, BCBS 239, DORA, GDPR, EBA, SSM, SREP, ICAAP, and a dozen more. Most explanations of these regulations are written by lawyers for lawyers.
This post is written by a data engineer for data engineers. I will explain what each regulation actually demands from your data — not the legal theory, the concrete data requirements.
The Architecture First: Who Makes the Rules and Who Enforces Them
Before diving into the regulations, understand the three-layer architecture:
- Layer 1 — Global standards (BCBS): The Basel Committee on Banking Supervision publishes principles and standards. These are not law — they are internationally agreed standards that the EU then legislates into binding law.
- Layer 2 — EU rulemaking (EBA, European Commission): The European Banking Authority translates global standards into EU-specific binding technical standards. The European Commission adopts them as law. The EBA also publishes the COREP reporting templates and XBRL taxonomy that banks must use.
- Layer 3 — National supervision (ECB, BaFin, DNB, Banca d’Italia): National regulators supervise individual banks. They receive COREP submissions, run SREP reviews, and impose penalties. The ECB directly supervises the ~110 largest EU banks through the Single Supervisory Mechanism.
Each regulation I cover below sits at one of these layers. Understanding the layer tells you who can penalise you for non-compliance.
CRR — Capital Requirements Regulation
What It Is
CRR (EU Regulation 575/2013, amended by CRR2 in 2019 and CRR3 in 2024) is the core quantitative rulebook for EU banks. It is an EU Regulation — meaning it is directly applicable in every EU member state without any national legislation needed. Every bank in the EU, from Deutsche Bank to a small Finnish cooperative bank, is subject to identical CRR rules.
CRR implements the Basel III/IV capital and liquidity standards into EU law. If you read CRR, you are essentially reading the EU version of the Basel Accords.
The Three Pillars
CRR operates through a three-pillar structure inherited from Basel II:
Pillar 1 — Minimum Requirements: The quantitative floors every bank must meet. These are the numbers regulators check first:
| Ratio | Formula | Minimum |
|---|---|---|
| CET1 Ratio | Common Equity Tier 1 Capital ÷ Risk-Weighted Assets | 4.5% |
| Tier 1 Ratio | (CET1 + Additional Tier 1) ÷ Risk-Weighted Assets | 6.0% |
| Total Capital Ratio | (CET1 + AT1 + Tier 2) ÷ Risk-Weighted Assets | 8.0% |
| Leverage Ratio | Tier 1 Capital ÷ Total Exposure (no risk weights) | 3.0% |
| LCR (Liquidity) | High Quality Liquid Assets ÷ Net Cash Outflows (30 days) | 100% |
| NSFR (Liquidity) | Available Stable Funding ÷ Required Stable Funding | 100% |
Every number on this table is calculated from data. Every ratio has a numerator and a denominator, and each of those is the result of hundreds of data transformations applied to millions of individual transactions. This is why the data pipeline you build to produce these numbers must be reliable, traceable, and governed.
Pillar 2 — Supervisory Review: The supervisor assesses whether Pillar 1 is enough for a specific bank’s risk profile. Each bank produces an ICAAP (Internal Capital Adequacy Assessment Process) — a self-assessment of all risks and the capital needed to cover them. The regulator responds with an SREP (Supervisory Review and Evaluation Process), which may impose a Pillar 2 add-on. A bank with weak data governance can receive a capital add-on under Pillar 2 specifically because the supervisor cannot trust the Pillar 1 numbers.
Pillar 3 — Market Discipline: Banks publicly disclose risk and capital information so investors and counterparties can make informed decisions. These public disclosures must be consistent with the private COREP supervisory submission. A discrepancy between what you tell the regulator and what you tell the market is itself a supervisory finding.
What Data CRR Demands
To calculate just the CET1 ratio you need:
- Every capital instrument classified by tier (CET1, AT1, Tier 2)
- Every regulatory deduction (goodwill, intangibles, deferred tax assets, pension deficits)
- Every loan and exposure classified into one of the CRR exposure classes
- Risk weights per exposure (from external credit ratings or internal models)
- Collateral and guarantees that reduce exposure values
- Market risk positions and sensitivities for the trading book
- Operational risk data (business indicator components, loss history)
That data feeds COREP — the Common Reporting framework. COREP is the set of templates (over 100 in total) that banks complete and submit to their national regulator in XBRL format every quarter. In this project I am building a pipeline that produces valid COREP submissions for templates C 01.00 (capital composition), C 02.00 (risk-weighted assets), C 03.00 (capital ratios), and C 47.00 (liquidity coverage ratio).
What Changed With CRR3 (Basel IV, January 2025)
CRR3 introduced the most significant change to bank capital calculations since 2008: the output floor. Banks that use their own internal models to calculate risk-weighted assets can no longer produce an RWA figure below 72.5% of what the standardised approach would produce. This closes a loophole where sophisticated banks gamed their models to hold far less capital than simpler banks on identical portfolios. The data implication: every IRB bank now needs to calculate both its model-based RWA and the standardised RWA simultaneously — roughly doubling the credit risk data processing requirement.
CRD — Capital Requirements Directive
CRD (Directive 2013/36/EU, updated as CRD V and CRD VI) is the governance counterpart to CRR. Where CRR gives you the quantitative rules, CRD gives you the governance rules: board composition and qualifications, remuneration structures, internal governance frameworks, supervisory powers.
CRD is a Directive — it requires national implementation. Each country passes its own law (Germany: KWG, Netherlands: Wft, Italy: TUB) that transposes CRD into national legislation. This creates some variation between countries in how governance requirements are implemented.
For a data engineer, the most relevant CRD provision is Article 74: banks must have robust internal governance arrangements including a clear organisational structure, effective processes for identifying, managing, and reporting all material risks, and adequate internal control mechanisms. CRD Art. 74 is the legal basis for requiring a data governance framework — it is not optional.
BCBS 239 — The Data Governance Standard Nobody Talks About But Everyone Follows
What It Is
BCBS 239 is not an EU regulation. It is a set of principles published by the Basel Committee on Banking Supervision in January 2013, titled “Principles for effective risk data aggregation and risk reporting.” It has 14 principles divided into four categories.
It is not legally binding in itself — but the ECB explicitly assesses BCBS 239 compliance as part of its annual SREP review. A low BCBS 239 maturity score leads to a higher Pillar 2 capital requirement. So while BCBS 239 is technically voluntary, its financial consequences make it effectively mandatory for every significant institution.
Why It Exists
During the 2008 financial crisis, regulators discovered something alarming: major global banks could not tell their own boards, or the regulators, what their total exposure to Lehman Brothers was. Not because the data did not exist somewhere — but because it lived across hundreds of siloed systems, required weeks of manual aggregation, and by the time a number was produced, it was already stale and nobody could verify it was correct.
BCBS 239 is the direct response. It says: you must be able to produce accurate, complete, timely risk data on demand — especially in a crisis, when you need it most and have the least time to compile it manually.
The 14 Principles in Plain English
The 14 principles fall into four groups:
Governance and Infrastructure (Principles 1–2):
- Principle 1 — Governance: The board is personally accountable for data quality. Named individuals must own each data domain. No more “the system produced that number.”
- Principle 2 — Data Architecture: Your data infrastructure must be designed to support risk aggregation — not bolted together from spreadsheets and manual processes. This principle is the entire architectural foundation of the pipeline I am building.
Risk Data Aggregation (Principles 3–6):
- Principle 3 — Accuracy: Data must be accurate and largely automated. If your capital calculation requires manual adjustments, that is a finding.
- Principle 4 — Completeness: All material exposures must be captured. You cannot exclude a business line because it is hard to aggregate.
- Principle 5 — Timeliness: Data must be available when needed. For COREP: within 12 business days of quarter-end. For intraday LCR during a crisis: same day.
- Principle 6 — Adaptability: You must be able to re-run reports with different parameters on demand. If an ad hoc supervisor request takes three weeks to answer, that is a finding.
Risk Reporting (Principles 7–11):
- Principle 7 — Accuracy in reporting: Reports must be accurate. Cross-template consistency checks (C 03.00 ratios must match C 01.00 capital divided by C 02.00 RWA) are part of this.
- Principle 8 — Comprehensiveness: Reports must cover all material risks.
- Principle 9 — Clarity: Reports must be understandable. A dashboard that needs a PhD to interpret fails this principle.
- Principle 10 — Frequency: Reports must be produced at the right cadence — more frequently during stress.
- Principle 11 — Distribution: Reports must reach the right people with appropriate access controls. Not everyone should see everything.
Supervisory Review (Principles 12–14):
- Principles 12–14 cover how supervisors assess, remediate, and cooperate across borders on data governance.
How BCBS 239 Maps to This Pipeline
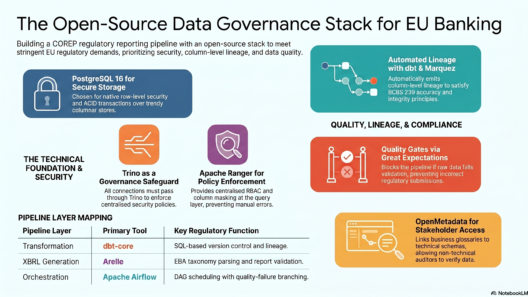
Every engineering decision in this project can be traced to a BCBS 239 principle:
| Principle | Engineering Implementation |
|---|---|
| P1 — Governance | OpenMetadata Data Owner and Data Steward tags on every table |
| P2 — Data Architecture | The entire modular pipeline design — PostgreSQL, dbt, Airflow, Marquez |
| P3 — Accuracy | Great Expectations quality suites + Arelle XBRL formula validation |
| P4 — Completeness | dbt not_null tests on all mandatory columns, all 8 CRR exposure classes required |
| P5 — Timeliness | Airflow scheduled pipeline with SLA monitoring on audit.pipeline_run_log |
| P6 — Adaptability | python pipeline.py –from quality re-runs from any point on demand |
| P7 — Report accuracy | Arelle cross-template formula validation before XBRL submission |
| P11 — Distribution | Apache Ranger RBAC — role_dashboard_reader, role_xbrl_reader, role_auditor |
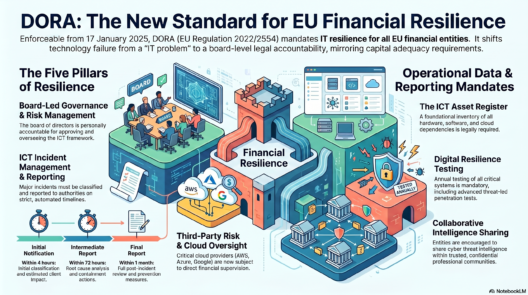
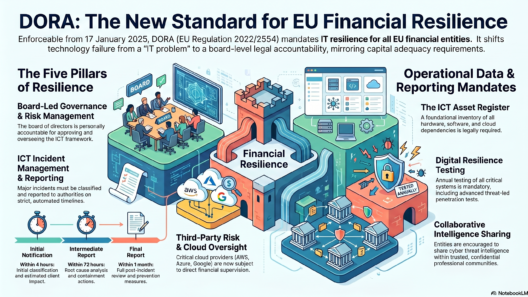
DORA — Digital Operational Resilience Act
What It Is
DORA (EU Regulation 2022/2554) became fully applicable on 17 January 2025. It is the EU’s answer to a risk that Basel and CRR largely ignored: what happens when a bank’s IT systems stop working?
Before DORA, ICT risk in banking was addressed through a patchwork of national guidelines — BaFin’s BAIT in Germany, the FCA’s CBEST in the UK, EBA guidelines that were advisory rather than binding. Each was different. A bank operating in five EU countries faced five different ICT risk frameworks with five different definitions, five different reporting formats, and five different supervisory expectations.
DORA ends that fragmentation. Like CRR for capital, it is a single regulation directly applicable across all EU member states, covering every type of financial entity — not just banks, but payment institutions, investment firms, insurance companies, crypto-asset service providers, and for the first time, the major cloud providers (AWS, Azure, Google Cloud) that provide critical services to them.
The Five Pillars
Pillar 1 — ICT Risk Management (Art. 5–16): The board is personally accountable for ICT risk. Banks must maintain a complete, up-to-date inventory of every ICT asset, its function, its dependencies, its recovery time objective, and its security configuration. No more “we don’t know what systems we have” — a genuine problem at many banks before DORA.
Data captured: ICT asset register (every system, its owner, its classification as critical/important/supporting, RTO, RPO, patch status, encryption status, interconnections with other systems).
Pillar 2 — Incident Management and Reporting (Art. 17–23): Every ICT incident must be logged and classified. Major incidents — those meeting materiality thresholds for client impact, downtime duration, or data loss — must be reported to the national regulator within 4 hours of classification, with an intermediate report within 72 hours and a final post-incident review within one month.
Data captured: Incident log (timestamp, type, affected systems, downtime duration, clients affected, root cause, classification decision, report timestamps). This is the data equivalent of a financial incident report — every field is evidence.
Pillar 3 — Resilience Testing (Art. 24–27): Annual testing of all ICT systems supporting critical functions — vulnerability scans, penetration tests, disaster recovery tests. The largest banks must conduct TLPT (Threat-Led Penetration Testing) using the TIBER-EU framework, which simulates real threat actor behaviour against production systems, every three years.
Data captured: Testing register (test type, systems covered, date, tester, findings by severity, remediation deadlines, remediation status). A critical finding not remediated on time is itself a regulatory breach.
Pillar 4 — Third-Party Risk Management (Art. 28–44): The most operationally complex pillar. Banks must maintain a Register of Information covering every ICT service provider arrangement — including the full sub-outsourcing chain. Every ICT contract must contain specific DORA-mandated provisions including audit rights, exit strategy provisions, data portability rights, and incident notification SLAs. The ESAs designate the most critical cloud providers as CTPPs (Critical Third-Party Providers) — subject to direct supervisory oversight for the first time.
Data captured: Third-party register (vendor name, LEI, service type, function supported, critical/important flag, data storage country, sub-outsourcing chain, contract dates, exit plan status, concentration risk assessment, SLA performance).
Pillar 5 — Information Sharing (Art. 45–49): Banks may — and are encouraged to — share cyber threat intelligence with each other through trusted community arrangements. DORA formalises and protects these sharing activities, which previously sat in a legal grey area around competition law and confidentiality obligations.
Data captured: Threat intelligence log (source, threat type, indicators of compromise, actions taken, TLP classification).
DORA and BCBS 239 — The Same Problem from Different Angles
BCBS 239 Principle 2 says: “A bank should have robust data architecture and IT infrastructure.” DORA Art. 8 says: “Maintain an updated register of all ICT assets and their interconnections.” They are describing the same requirement. A strong response to one largely answers the other. In a supervisory examination, your Marquez lineage graph (which documents data flows between systems) contributes evidence for both BCBS 239 Principle 2 and DORA Art. 8.
GDPR — General Data Protection Regulation
What It Is
GDPR (EU Regulation 2016/679, applicable since May 2018) needs less introduction than the others. Most people encounter it through cookie consent banners. For a banking data engineer, it creates four concrete engineering constraints that sit on top of every other regulation:
- Minimization: Collect and process only the personal data you actually need
- Protection: Implement access controls, encryption, and masking
- Traceability: Know where every piece of personal data is and who accessed it
- Removability: Be able to respond to subject access requests and erasure requests
What Counts as Personal Data in a Banking Pipeline
In a corporate banking context you might assume most data is about legal entities — companies, institutions — not natural persons. This assumption fails in several places:
- Retail loan data — individual borrowers are natural persons. Their names, balances, credit history are personal data.
- Sole traders and partnerships — the legal entity is the natural person.
- Beneficial owners and directors — named individuals in corporate structures.
- Bank employees — anyone who approves a credit decision, owns a data asset in OpenMetadata, or whose username appears in an audit log.
- IP addresses — explicitly listed as personal data in GDPR Art. 4(1).
For the COREP pipeline in this project, the personal data concern centres on raw.counterparties (retail loan counterparties are natural persons) and raw.loans (which links to counterparties via a foreign key).
The Legal Basis for Processing
GDPR Art. 6 requires a legal basis for every processing activity. For regulatory reporting, the basis is Art. 6(1)(c) — legal obligation: the bank is required by CRR to calculate and report capital requirements. Processing the underlying loan data to produce a COREP submission is legally mandated — no customer consent is needed. But the processing must still be proportionate and minimized.
Pseudonymization — The Key Technique
Pseudonymization (GDPR Art. 4(5)) means replacing a personal identifier with a pseudonym, where the original can only be recovered using a separately held mapping key. It is not the same as anonymization — pseudonymized data is still personal data under GDPR, but it carries substantially reduced risk and GDPR’s Recital 26 treats it more favourably.
In this pipeline, pseudonymization works as follows:
raw.counterpartiesstores:counterparty_id = CP-000142,lei = DE89***1234(partial mask),name = C*****y GmbH(masked)- A separate
mapping.counterparty_piitable (accessible only torole_pii_admin) holds the real name and full LEI - All dbt staging models use only the pseudonymized ID — they never SELECT the name or full LEI columns
- The mart layer, XBRL output, and final regulatory submission contain no personal data at all — only aggregated capital and liquidity numbers
Apache Ranger enforces column masking: role_dashboard_reader sees a partially masked LEI and masked name. No code in Superset is needed — the masking happens at the query engine layer before the data reaches the dashboard.
Data Minimization in Practice
GDPR Art. 5(1)(c) requires that personal data be “adequate, relevant and limited to what is necessary.” For COREP reporting, this means asking a precise question: which columns of personal data are actually needed to calculate the capital ratios?
The answer is: none of the four COREP templates I am building require a counterparty’s name or full LEI. The risk weight depends on the counterparty’s exposure class (corporate, retail, sovereign) and credit rating — both of which are non-personal attributes. The staging model excludes the name and LEI columns entirely:
-- staging/stg_counterparties.sql
SELECT
counterparty_id, -- pseudonymized ID — not personal data
sector, -- not personal data
country, -- not personal data
credit_rating, -- not personal data
-- name excluded — not needed for any COREP calculation
-- lei excluded — not needed for any COREP calculation
current_timestamp AS _loaded_at
FROM raw.counterpartiesData minimization is enforced architecturally. It is not possible to accidentally include personal data in the mart layer because it was never admitted to the staging layer.
GDPR and the Tension With Other Regulations
GDPR data minimization and CRR data retention pull in opposite directions. GDPR says: delete personal data when no longer needed. CRR Art. 74 says: keep records for 7 years. AMLD6 says: keep AML records for 5 years.
The resolution is a two-tier model:
- Tier 1 — Pseudonymized records: Individual loan and exposure records with names removed, kept for 7 years (satisfies CRR). No personal data — GDPR minimization satisfied.
- Tier 2 — PII mapping table: Real names and LEIs, accessible only to
role_pii_admin. Deleted when the legal basis expires (7 years from loan closure). Erasure requests honoured by deleting from this table — the pseudonymized record survives for regulatory purposes.
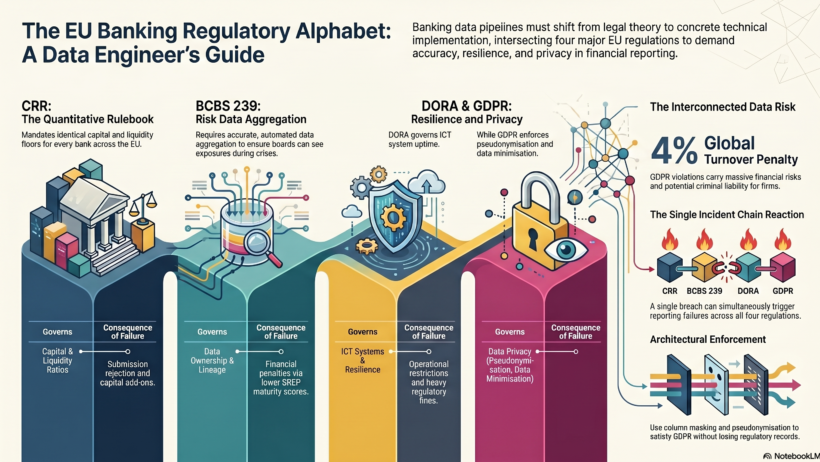
How the Four Regulations Work Together
These regulations are not independent — they form a single governance framework where each fills a gap the others leave:
| Regulation | Governs | What it demands from your data | Consequence of failure |
|---|---|---|---|
| CRR | Capital and liquidity numbers | Accurate, complete, timely quantitative data for ratio calculations and COREP submission | Supervisory breach, capital add-on, submission rejection |
| BCBS 239 | How data is governed and produced | Data ownership, lineage, quality framework, completeness, aggregation capability | Pillar 2 capital add-on via SREP, supervisory finding |
| DORA | ICT systems that produce the data | ICT asset register, incident log, third-party register, resilience testing data | Supervisory finding, fines, operational restrictions |
| GDPR | Personal data within all the above | Pseudonymization, minimization, access controls, audit trail, retention and erasure | Up to 4% of global annual turnover, criminal liability |
A single data pipeline failure can trigger all four simultaneously. A cyberattack that corrupts your capital data is: a CRR reporting failure (wrong numbers submitted), a BCBS 239 failure (inadequate data architecture), a DORA Major Incident (requiring supervisor notification within 4 hours), and potentially a GDPR breach (if personal data was accessed). Four regulators. One incident.
What the Pipeline in This Series Does About All of This
Every module in the COREP pipeline maps to one or more of these regulations:
| Module | Regulation It Satisfies |
|---|---|
ingest — source data load | CRR (complete source data), BCBS 239 P4 (completeness) |
quality — Great Expectations | BCBS 239 P3 (accuracy), CRR (correct inputs to ratio calculation) |
transform — dbt models | BCBS 239 P2 (architecture), BCBS 239 P6 (adaptability) |
catalog — OpenMetadata | BCBS 239 P1 (governance, ownership), CRD Art. 74 (internal governance) |
security — Apache Ranger | GDPR (access controls, PII masking), BCBS 239 P11 (distribution), DORA P1 (access controls) |
| Lineage — Marquez + OpenLineage | BCBS 239 P2 (data architecture), DORA Art. 8 (interconnection mapping) |
xbrl-gen + xbrl-valid — Arelle | CRR COREP ITS (submission format), BCBS 239 P7 (report accuracy) |
| Audit log — pg_audit + pipeline_run_log | GDPR (traceability), DORA P2 (incident evidence), BCBS 239 P1 (accountability) |
What’s Next
Tomorrow is Day 3 — COREP deep dive. I will download the actual EBA COREP templates, walk through every row of C 01.00 (capital composition) and C 47.00 (liquidity coverage ratio), download the EBA XBRL taxonomy, and open a real sample XBRL instance file in Arelle. By the end of Day 3 I will know exactly what data needs to come out of the pipeline and in exactly what format.
If you have questions about any of the regulations covered today — especially how they interact in practice — drop them in the comments below.
All code for this project will be open source on GitHub. Follow along for 16 more days.