Day 4 of 18 — Building a COREP regulatory reporting pipeline with open-source tools only.
When I started this project, the first question I asked myself was not “which tools should I use?” It was “what does a regulator actually care about when they receive a COREP report?”
The answer is surprisingly precise. A regulator cares that:
- The numbers are accurate — traceable back to source data
- The data hasn’t been tampered with — immutable audit trail
- Only the right people touched the right data — access logs
- The same calculation will produce the same result tomorrow — reproducibility
- If something breaks, you can explain exactly why — lineage and quality gates
Every tool in this stack was chosen because it answers at least one of those five demands. No tool was added because it is trendy. Some popular tools were explicitly rejected — I’ll tell you why.
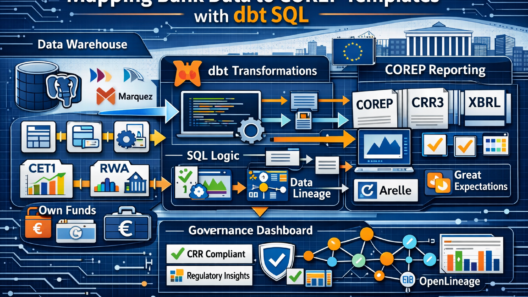
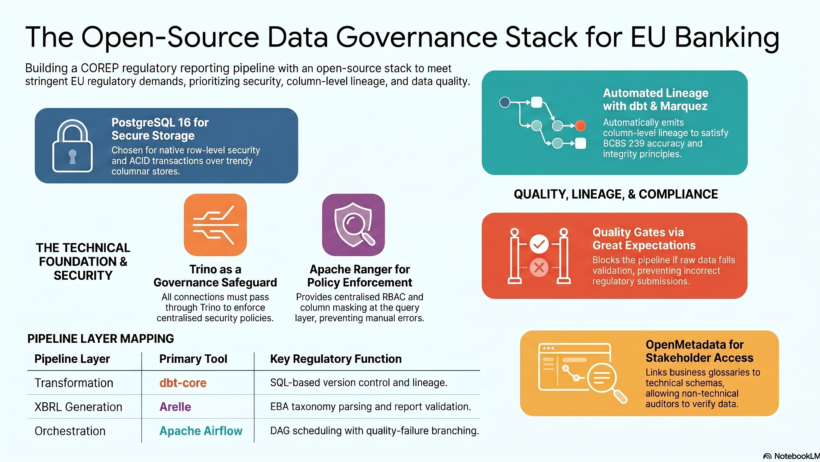
The Complete Stack — One View
| Layer | Tool | What it does in this pipeline |
|---|---|---|
| Storage | PostgreSQL 16 | All schemas: raw, staging, mart, audit |
| Object Store | MinIO | XBRL output, EBA source files, audit logs as Parquet |
| Query Federation | Trino | Single SQL interface — all consumers use Trino only |
| Iceberg Catalog | Project Nessie | Git-like catalog for Iceberg tables on MinIO |
| Transform | dbt-core | Staging → intermediate → mart, column lineage auto-emitted |
| Lineage | Marquez + OpenLineage | Column-level + pipeline-level lineage from day one |
| Data Quality | Great Expectations | Expectation suites on raw and mart tables |
| Data Catalog | OpenMetadata | Auto-discovery, COREP glossary, PII tags, data contracts |
| Security | Apache Ranger | RBAC, column masking, row filters — tag-driven |
| Orchestration | Apache Airflow | DAG scheduling, branch on quality failure |
| XBRL | Arelle | EBA taxonomy parsing, XBRL instance generation, validation |
| Dashboards | Apache Superset | Capital dashboard + Governance Audit dashboard |
Now let me explain the reasoning behind each choice — and what I rejected in its place.
1. PostgreSQL 16 — Not a Compromise, a Deliberate Choice
The first question people ask is: “Why PostgreSQL and not a columnar store like ClickHouse or DuckDB?”
For a COREP pipeline, the data volumes are modest. A large EU bank submits COREP with roughly 50,000–200,000 rows per reference date across all templates. PostgreSQL handles that in milliseconds. What PostgreSQL gives you that no columnar store does out of the box is:
- Row-level security — native, no plugins needed
- pg_audit extension — DDL and DML audit logging backed into the engine
- Schema isolation — raw, staging, intermediate, mart, audit, secure as first-class namespaces
- ACID transactions — critical when you are writing regulatory numbers
I also wanted a storage layer that every data engineer already knows. Nobody should need to learn a new query engine just to contribute to a governance project.
Rejected alternative: ClickHouse. Excellent for analytics, but no native RBAC at the row level, and the audit story requires third-party plugins that are not production-hardened for regulatory use.
2. Trino — The Rule That Protects You From Yourself
Early in the design I made one rule: no application, no dashboard, no script connects directly to PostgreSQL. Everything goes through Trino.
This sounds like unnecessary complexity. It is actually a governance safeguard.
Trino is the enforcement point for Apache Ranger security policies. Column masking, row-level filters, and role-based access are all defined in Ranger and enforced at the Trino query layer. If Superset connects directly to PostgreSQL, it bypasses all of that. One mis-configured Superset dataset would expose raw PII to a dashboard reader.
Trino also future-proofs the architecture. Today the data is in PostgreSQL. Tomorrow you might add an S3 data lake or a second database. Consumers (Superset, the xbrl-gen module) never change their connection string — only the Trino catalog configuration changes.
Rejected alternative: Direct PostgreSQL connections with application-level access control. Rejected because application-level controls are only as good as the developer who wrote the WHERE clause.
3. Apache Iceberg + Project Nessie — The Audit Log You Can Time-Travel
The Apache Ranger audit logs — every query, every policy evaluation, every access decision — need to be:
- Stored immutably (you cannot alter an audit log)
- Queryable (a regulator may ask for all queries against mart.corep_c0100 in Q4 2025)
- Cheap to store at volume (logs grow fast)
Apache Iceberg on MinIO delivers all three. Iceberg tables are stored as Parquet files on object storage.
They support time travel — SELECT * FROM audit.ranger_logs FOR SYSTEM_TIME AS OF '2025-12-31'
is a valid query. Project Nessie adds a Git-like catalog layer: you can create a branch of the audit
table, run analysis on it, and merge it back — without touching the immutable main branch.
Rejected alternative: Hive Metastore. Functionally equivalent for table registration, but requires a running Hive service with its own database. Nessie is a single lightweight JAR with a REST API. For a learning project it is dramatically simpler, and for production it is increasingly the industry standard.
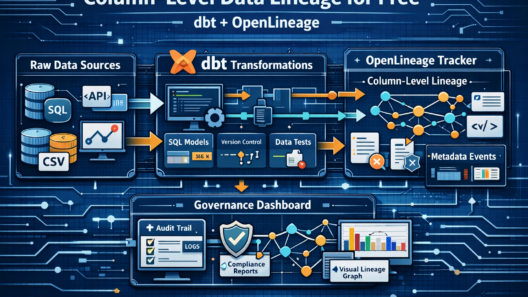
4. dbt-core — Transforms Are Documentation
I chose dbt for one reason that has nothing to do with SQL templating or macros: every dbt model is automatically a lineage node.
When you install dbt-openlineage alongside dbt, every dbt run emits an
OpenLineage event to Marquez describing exactly which columns from which source tables were used
to compute which output columns. This is column-level data lineage with zero extra code.
For BCBS 239 compliance (Principle 3: Accuracy and Integrity), you need to demonstrate that every number in a regulatory report can be traced to its source. dbt + OpenLineage gives you that trace automatically, versioned in Git, re-runnable at any point in time.
The three-layer model — staging → intermediate → mart — also enforces data governance
architecturally. Staging models exclude PII columns entirely. This is not a policy document; it is
a SQL file checked into version control. GDPR data minimization becomes code.
Rejected alternative: SQLMesh. Technically superior in some ways (virtual environments, better state management), but the OpenLineage integration is less mature and the learning curve for someone new to the space is higher.
5. Marquez — Lineage Starts on Day One, Not Day Fourteen
The original instinct was to add Marquez at the end of the project, once the pipeline was working. This was wrong. I added it to the docker-compose file on Day 1.
The reason is simple: if you add a lineage tool after you build a pipeline, you discover that your emitters were never configured correctly, your column names are inconsistent between the OpenLineage events and the actual table schema, and you have no historical runs to reference. Lineage must be captured from the very first run, or it has no value.
Marquez is purpose-built for OpenLineage events. It has a clean REST API, a visual graph UI, and supports run-level metadata (duration, row counts, schema at time of run). It is the operational lineage backend. OpenMetadata then pulls from Marquez to present lineage in governance context alongside catalog metadata and data quality scores.
6. Great Expectations — Quality Gates That Stop the Pipeline
Data quality in regulatory reporting is not optional. If your LCR ratio is computed from an outflow table that has NULL stress rates for 15% of rows, your COREP submission is wrong. The regulator does not care that your pipeline ran successfully.
Great Expectations solves this by running expectation suites as checkpoints. The Airflow DAG
branches on the result: if quality checks pass, the pipeline continues to dbt transform.
If they fail, the DAG routes to a notify_failure task and stops. No bad data
reaches the COREP mart.
The HTML data docs output is also a governance artifact — a timestamped, shareable quality report for every pipeline run, stored on MinIO.
Rejected alternative: dbt tests only. dbt tests are excellent for mart-layer validation (not null, unique, referential integrity). But they run after the transform. Great Expectations runs on the raw layer before the transform, which is where bad data should be caught.
7. OpenMetadata — The Governance Layer That Connects Everything
OpenMetadata is the one tool in this stack that a non-technical stakeholder — a compliance officer, a data steward, an internal auditor — can use without knowing SQL.
It provides:
- Data catalog: every table, every column, with descriptions and owners
- COREP glossary: business terms linked to physical columns (e.g., “CET1 Capital” →
mart.corep_c0100.r010_cet1_capital) - PII tagging: columns tagged as PII in OpenMetadata automatically trigger column masking policies in Apache Ranger
- Data contracts: formal agreements between data producers and consumers, versioned
- Lineage view: visual graph pulled from dbt manifest and Marquez, presented alongside catalog context
The PII tag → Ranger policy integration is the most powerful governance feature in the entire stack. You tag a column once in the catalog. The security enforcement happens automatically at the query layer. No manual Ranger policy authoring per column.
Rejected alternative: DataHub. Comparable feature set, but the self-hosted deployment is heavier (requires Kafka, more services). OpenMetadata runs cleanly in Docker Compose with MySQL and Elasticsearch.
8. Apache Ranger — Centralised Security, Not Application-Level Guards
Most data pipelines enforce access control at the application layer: a Python script checks if the user has a role before running a query. This is fragile — it only works if every application implements the check correctly, every time.
Apache Ranger enforces access control at the query engine layer. A policy that says
“mask the lei column for anyone in role_dashboard_reader”
is enforced in Trino before the query result is returned. It doesn’t matter which application
issues the query.
This is the architecture that passes a regulatory data governance audit. The control is centralised, logged, and not dependent on application developer discipline.
9. Arelle — The XBRL Engine That Regulators Actually Use
Arelle is the reference implementation for XBRL processing. The EBA uses it internally to validate submitted reports. When you use Arelle to generate and validate your XBRL instance, you are using the same validation engine as the supervisor. There is no ambiguity about whether a validation error is a tool artefact or a real compliance issue.
It is also the only mature open-source XBRL library with full EBA taxonomy support and active maintenance as of 2026. The choice was straightforward.
The One Tool I Almost Added and Didn’t
Apache Atlas. It is the original open-source data catalog, developed at Hortonworks and tightly integrated with the Hadoop ecosystem. In 2026, it is largely superseded for new projects by OpenMetadata and DataHub. The UI is dated, the Ranger integration requires manual configuration for every policy, and the OpenLineage support is community-contributed rather than first-class. OpenMetadata does everything Atlas does, with a better UI and native lineage integration.
Why Open-Source for Regulatory Reporting?
A fair question: commercial tools like Collibra, Alation, and Informatica exist. Why build this on open source?
Three reasons:
- Auditability. When a regulator asks “how does your pipeline compute CET1 capital?”, the answer is a dbt SQL file in a Git repository with a full commit history. There is no black box. Every transformation is readable, versioned, and explainable.
- Portability. The entire stack runs in Docker Compose. It can run on a laptop, a private data centre, or a cloud VPC. There is no vendor lock-in at the infrastructure layer.
- Learning transfer. Every tool in this stack is used by production engineering teams at major financial institutions. Learning them on an open-source project translates directly to production work.
Next Post
Day 5: Simulating a bank’s data for COREP — how to generate synthetic capital, RWA, and liquidity data that is statistically realistic, GDPR-safe, and calibrated against real EBA Transparency Exercise data.