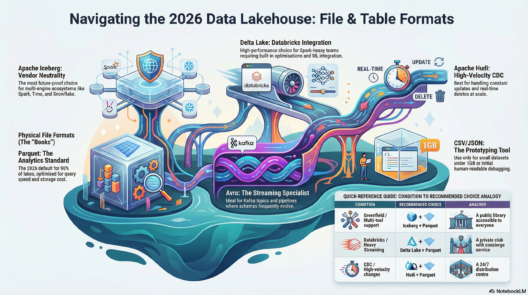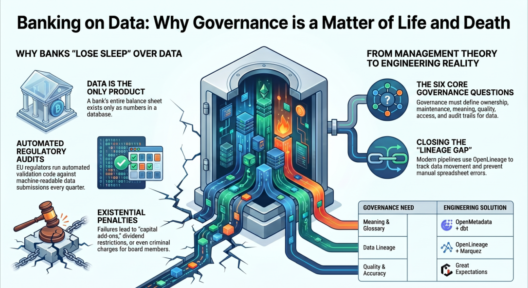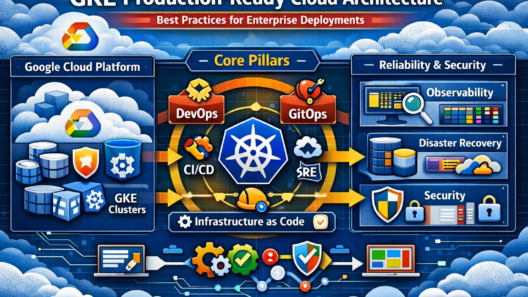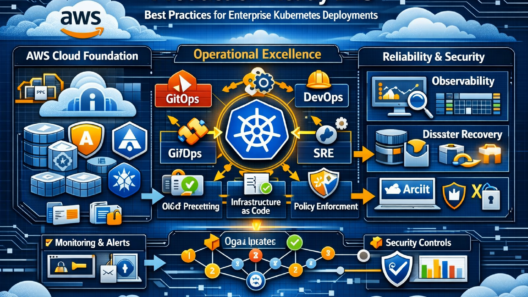
In today’s world, users expect digital experiences to behave like electricity — always on, instantly responsive, and quietly reliable. The moment your system slows down, goes dark, or behaves unpredictably, users don’t just get annoyed… they leave. And they rarely come back.
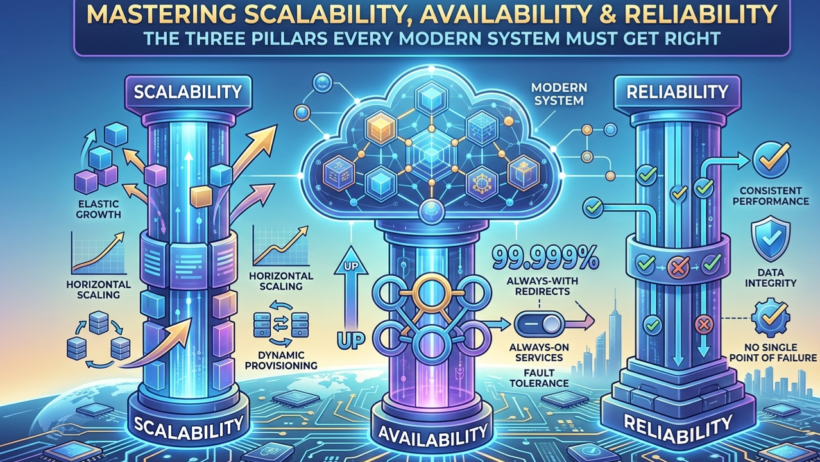
That’s why Scalability, Availability, and Reliability aren’t just technical goals — they’re the survival instincts of modern systems. They define whether your platform thrives under pressure or collapses under its own success.
Let’s break them down in a way that sticks.
What These Pillars Really Mean (Explained Through Everyday Life)
Scalability — Can You Handle Growth Without Breaking a Sweat?
Think of a restaurant on a Friday night.
A scalable restaurant can add more chefs, more stoves, or even open a second kitchen. A non-scalable one forces customers to wait two hours while a single exhausted chef tries to cook for 200 people.
In systems, scalability is the ability to grow without performance falling off a cliff.
Availability — Are You There When Users Need You?
Availability is uptime — plain and simple.
Imagine turning on your tap and nothing comes out. Even if it happens once or twice a year, it’s unacceptable. That’s how users feel when your service goes down for “just 30 minutes.”
Reliability — Does Your System Do the Right Thing Every Time?
Your car doesn’t just need to “run.” It needs to start every morning, handle long drives, and behave predictably even when something goes wrong.
A system is reliable when it:
- returns correct results
- handles failures gracefully
- recovers without drama
A service can be “up” but still unreliable — and that’s often worse.
Real-World Use Cases (Where These Pillars Decide Winners & Losers)
Planet-Scale Distributed Systems
Google Spanner, Amazon DynamoDB — these aren’t databases, they’re global organisms. They shard, replicate, and self-heal across continents so developers can pretend the world is one giant data center.
Cloud-Native Microservices
Kubernetes + Istio is the modern factory floor. Thousands of pods spin up and down like breathing. Traffic shifts automatically. Security is baked in.
High-Traffic Consumer Apps
- Amazon handles millions of orders per second on Prime Day.
- Netflix streams 250M+ hours daily using edge appliances and auto-scaling microservices.
- Stripe processes billions in payments with strict consistency where it matters and eventual consistency where it doesn’t.
These companies don’t “hope” their systems scale — they engineer for it.
Common Pitfalls (Even Senior Engineers Fall Into These)
- Over-scaling too early
Burning money on giant clusters “just in case.” - Misreading SLAs
99.99% uptime still means almost an hour of downtime a year. - Cascading failures
One slow service → thread exhaustion → total meltdown. - Stateful services everywhere
Sticky sessions and in-memory state kill horizontal scaling. - Guess-based capacity planning
“It should handle the load” is not a strategy.
Architectural Considerations (The Real System Design Playbook)
Load Balancing
Modern L7 balancers (ALB, Envoy, NGINX) route intelligently, warm up slowly, and avoid hot spots.
Replication
Choose your model:
- Leader–follower
- Multi-master
- Quorum-based
- CRDTs for conflict-free global writes
Each has trade-offs — choose based on consistency needs.
Caching
Use caching like seasoning: enough to enhance, not so much that it ruins the dish.
- CDN for static assets
- Redis/Memcached for hot data
- Local caches for micro-optimizations
Event-Driven Architecture
Kafka and Pulsar turn your system into a loosely coupled ecosystem. Producers don’t care who consumes. Consumers scale independently.
CAP Theorem
During a network partition, you must choose:
- CP → consistency first
- AP → availability first
Most real systems blend both.
Failure Isolation
Bulkheads, circuit breakers, cell-based architecture — these prevent small fires from becoming city-wide disasters.
Trends Shaping 2025–2026 (The Future Is Already Here)
- Serverless that actually scales predictively
AI-driven cold-start elimination and stateful functions. - Active-active multi-region by default
Global databases like CockroachDB and Spanner make it almost too easy. - Chaos engineering goes mainstream
Teams inject failure continuously to build muscle memory. - AI-powered autoscaling
Systems scale based on predicted demand, not CPU spikes. - Observability with intelligence
OpenTelemetry + AI anomaly detection = fewer 3 AM incidents. - Edge computing everywhere
Cloudflare Workers, Lambda@Edge, and 5G MEC push compute closer to users.
Recommendations & Best Practices (What Great Teams Actually Do)
Design for Elasticity
- Keep services stateless
- Store session data externally
- Use GitOps + IaC for reproducibility
- Scale based on business metrics, not just CPU
Measure Availability Properly
Use SLOs and error budgets. Track MTBF and MTTR.
Instrument everything — client-side, server-side, synthetic probes.
Build for Graceful Degradation
When things break (and they will), your system should bend, not snap.
Examples:
- Disable non-critical features
- Provide fallback UIs
- Use circuit breakers and timeouts
- Allow partial success
Choose Architecture Based on Load
- Small scale → monolith or simple K8s
- Global scale → microservices + events + multi-region + edge
And always test under real pressure before users do it for you.
Conclusion — The Systems That Win Are Built for the Unexpected
Scalability, availability, and reliability aren’t optional. They’re the foundation of trust. They determine whether your platform becomes a global success or collapses the moment it goes viral.
The best engineers don’t chase perfection — they design for failure, measure relentlessly, and embrace trade-offs with clarity. And as AI reshapes infrastructure, the winners will be the teams that combine human judgment with automated resilience.
Build for growth.
Design for failure.
Measure everything.
Your users — and your business — will feel the difference.