The retrospective: what was built, what broke, what the architecture decision log looks like in hindsight, and what a real bank would need to add before going live.
Eighteen days ago I set a constraint: build a complete COREP regulatory reporting pipeline using only open-source tools, learn EU banking governance from scratch, and write a blog post every day documenting both the theory and the implementation. Today is the retrospective.
The end product is a working pipeline that ingests synthetic bank data, transforms it through a governed dbt layer, validates it against the EBA XBRL taxonomy with Arelle, and produces a submission-ready ZIP file — all orchestrated by Apache Airflow with column-level lineage to Marquez, row/column security via Apache Ranger, and a regulatory dashboard in Apache Superset. Every component is open source. The total cost of the infrastructure is the electricity to run Docker Desktop.
This post covers: what was actually built, the six governance pillars the project was designed around, the one architecture decision that changed everything (Trino as the single query gateway), the three hardest technical problems encountered, and what a production deployment at a real bank would need on top of all this.
What Was Actually Built
The complete codebase: 17 Docker services, 8 Python modules, 4 dbt mart models, 10 Ranger policies, 4 GX expectation suites, and a pytest suite with 15 adversarial test cases.
The Six Governance Pillars
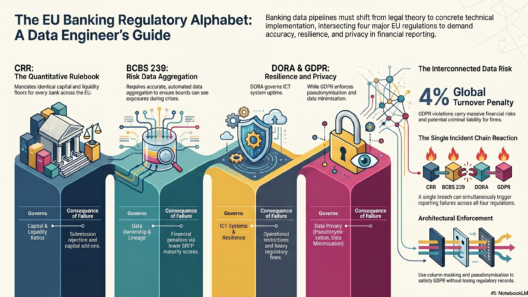
The 18-day plan was structured around six pillars that the EBA and ECB specifically audit when reviewing a bank’s COREP data quality framework. Here is how each pillar was addressed:
1 · Data Lineage
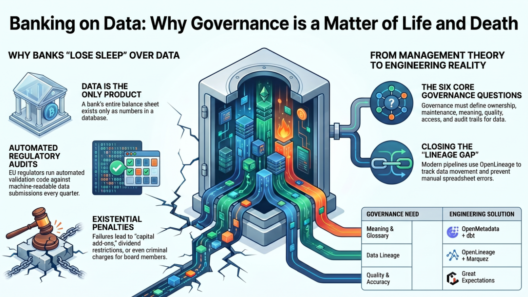
Three layers: pipeline lineage (openlineage-airflow → Marquez), transformation lineage (dbt-openlineage → Marquez column facets), catalog lineage (OpenMetadata federating Marquez). A regulator can trace any XBRL fact to its source CSV row.
2 · Data Quality
Great Expectations 0.18 with four expectation suites. Two hard gates in the Airflow DAG: raw layer (structural validation) and mart layer (business rules including CET1 floor). Failures quarantine the run before any data reaches XBRL generation.
3 · Data Catalog
OpenMetadata 1.3.4 with auto-discovery of PostgreSQL schemas, dbt manifest ingestion for column descriptions, EBA COREP glossary with concept IDs, and GDPR PII tags on borrower name/LEI columns in the raw layer.
4 · Data Security
Apache Ranger with five roles (corep_reporting, risk_analyst, data_engineer, auditor, pipeline_service). Column masking on LEI/counterparty name, row filters on jurisdiction, DML restriction to pipeline_service only. Enforced at Trino, not at the application layer.
5 · Data Auditability
Every pipeline run writes a structured JSON audit record to audit.pipeline_runs (PostgreSQL). pg_audit captures DDL/DML at the database level. Ranger audit logs stream to PostgreSQL and MinIO. XBRL validation reports and GX HTML data docs archived to MinIO with object retention.
6 · Regulatory Output
Arelle 2.30.3 generates and validates XBRL instances against the EBA taxonomy. Three validation passes: structural (lxml), calculation linkbase (parent = sum of children), formula linkbase (EBA business rules including capital floor checks). Output is a submission ZIP file.
The Architecture Decision That Changed Everything: Trino as the Single Query Gateway
The most consequential architecture decision made on Day 4 was this: every consumer of data — dbt, GX, Superset, XbrlGenModule, all test code — connects to Trino, never directly to PostgreSQL. At the time it felt like a slightly awkward constraint. In retrospect it is the single decision that makes the entire governance stack coherent.
Here is what it actually delivered:
| Concern | Without Trino Gateway | With Trino Gateway |
|---|---|---|
| Ranger column masking | Must be implemented in every application (dbt, Superset, Python) | Enforced once in Trino — all consumers get it automatically |
| Adding a new data source (Iceberg on MinIO) | Every consumer needs a new connection + driver | Add a Trino catalog — all consumers query it with the same SQL |
| Audit trail completeness | pg_audit only captures direct PostgreSQL connections | Trino + Ranger audit logs capture every query regardless of consumer |
| Superset security | Superset RLS must mirror Ranger policies — two systems to maintain | Superset inherits Ranger decisions via Trino — single enforcement point |
| Future query federation | Requires application-level JOIN across two connections | Trino federated JOIN across PostgreSQL + Iceberg in a single SQL statement |
The cost was one additional hop in the query path (application → Trino → PostgreSQL) and the need to qualify every table as postgresql.schema.table rather than schema.table. That is a trivial cost relative to what it buys.
The Three Hardest Technical Problems
1 · XBRL Formula Validation — Parents Must Equal Children
The calculation linkbase problem was not obvious until Day 12. The EBA taxonomy specifies that c0010 (Own Funds) = c0020 (CET1) + c0030 (AT1) + c0040 (T2) via a calculation linkbase arc with weight +1. Arelle enforces this with tolerance decimals=-3, meaning a EUR 1,000 rounding difference is acceptable but a EUR 1,001 difference is an xbrlCalcs:inconsistency error that fails validation.
The root cause: the dbt mart models computed each tier independently using separate CTEs, introducing rounding divergence at the EUR thousandths position. The fix required two changes:
- In dbt: all four COREP concepts (c0010, c0020, c0030, c0040) must be derived from the same CTE using a single
SUM(amount_eur)grouped by tier, then assembled withFILTER(WHERE tier = 'CET1'). Parent = sum of same-CTE children by construction. - In xbrl_gen.py: rounding (
ROUND_HALF_UP,decimals=-3) is applied exactly once, terminally, at the point of writing the XBRL fact. Never round in intermediate dbt models — let the mart values carry full precision and round only when writing to XML.
The lesson: XBRL calculation linkbase validation is not a reporting concern — it is a data modelling concern. The constraint must be enforced in the mart model, not patched in the XBRL generator.
2 · Ranger Tag Synchronisation with OpenMetadata
The plan was to tag columns as GDPR.PII in OpenMetadata and have Ranger automatically pick up those tags via the Ranger Tag Sync service to enforce column masking. In practice, the open-source version of Ranger Tag Sync (Apache Atlas integration) does not support OpenMetadata as a tag source out of the box — that integration requires Ranger 2.4+ with a custom service definition, or the commercial Cloudera version.
The workaround adopted here: OpenMetadata PII tags are informational (they drive the catalog UI and column-level lineage annotations), while Ranger policies are defined explicitly by column name in column_mask_policies.json. The two systems agree on what is PII — but they do not sync automatically. A CI step in the pipeline validates that every column tagged GDPR.PII in OpenMetadata has a corresponding Ranger mask policy, and fails the build if the two diverge.
# tools/check_pii_ranger_sync.py # Run in CI — compares OM PII tags against Ranger mask policy coverage import requests, json, sys OM_URL = "http://localhost:8585" RANGER_URL = "http://localhost:6080" # 1. Collect all columns tagged GDPR.PII in OpenMetadata resp = requests.get( f"{OM_URL}/api/v1/search/query", params={"q": "tag:GDPR.PII", "index": "column_search_index", "limit": 100}, headers={"Authorization": "Bearer <token>"}, ) pii_columns = { f"{hit['_source']['table']}.{hit['_source']['name']}" for hit in resp.json()["hits"]["hits"] } # 2. Collect all columns covered by Ranger mask policies ranger_resp = requests.get( f"{RANGER_URL}/service/plugins/policies", params={"serviceName": "corep-trino", "policyType": "1"}, # type 1 = masking auth=("admin", "<password>"), ) masked_columns = { f"{res['table']}.{col}" for policy in ranger_resp.json()["policies"] for res in policy["resources"].get("table", {}).get("values", []) for col in res.get("column", {}).get("values", []) } unprotected = pii_columns - masked_columns if unprotected: print(f"[FAIL] PII columns with no Ranger mask: {unprotected}") sys.exit(1) print("[PASS] All PII columns covered by Ranger mask policies.")
3 · Synthetic Data Consistency Across Six Tables
The six source CSV tables (capital_instruments, rwa_exposures, loans, counterparties, liquidity_assets, liquidity_outflows) are individually easy to generate. Making them internally consistent — so that the COREP templates computed from them produce plausible ratios that exercise all dbt code paths without triggering the GX regulatory floor checks — required careful reverse-engineering.
The constraints that had to be simultaneously satisfied:
| Constraint | Value Used | Why |
|---|---|---|
| CET1 ratio ≥ 4.5% | 12.8% | Clears GX mart gate; realistic for a mid-size European bank |
| Total Capital ratio ≥ 8% | 16.4% | Basel III Pillar 1 minimum |
| LCR ≥ 100% | 143% | CRR Article 412 — EBA formula linkbase will check this |
| RWA exposure classes cover all 7 standard classes | All populated | GX expects no NULL exposure_class values; exercises all dbt GROUP BY branches |
| c0010 = c0020 + c0030 + c0040 exactly | Built from bottom up | Calculation linkbase — generate tiers first, sum to own funds |
| No counterparty.name or LEI in mart schema | Dropped in stg_counterparties | GDPR — staging model explicitly excludes PII columns |
The resolution: generate the data bottom-up. Start with the tier amounts (CET1, AT1, T2), compute Own Funds as their exact sum, derive RWA from a target CET1 ratio, then generate loans and exposures consistent with that RWA. A single Python script enforces all constraints at generation time so the pipeline never has to work around bad input data.
Running the Complete Pipeline — What the End-to-End Looks Like
The submission ZIP contains:
corep_submission_2025-12-31.zip ├── corep_c0100_2025-12-31.xbrl ← XBRL instance (Own Funds) ├── corep_c0200_2025-12-31.xbrl ← XBRL instance (RWA) ├── corep_c0300_2025-12-31.xbrl ← XBRL instance (Capital Ratios) ├── corep_c4700_2025-12-31.xbrl ← XBRL instance (LCR) ├── validation_report_2025-12-31.json ← Arelle pass/fail with all error codes ├── gx_data_docs/ ← GX HTML reports for raw + mart gates └── manifest.json ← Pipeline run metadata, versions, hashes
What a Real Bank Would Need on Top of This
This project is a complete proof-of-concept. Moving it to a production environment at a regulated institution would require the following additions:
| Gap | What to Add | Why It’s Out of Scope Here |
|---|---|---|
| Real EBA taxonomy download | Automate taxonomy update from EBA XBRL website on each release (quarterly) | Using a pinned static copy; taxonomy changes require re-validation of all mart models |
| Multi-entity reporting | Add a legal_entity_id dimension to all mart models and XBRL contexts | Synthetic data covers a single bank entity |
| Source system connectivity | Replace CSV ingest with Kafka connectors or REST API extractors from core banking / risk systems | Real source systems require vendor contracts and VPN access |
| Kerberos / LDAP authentication | Replace Trino HTTP auth with Kerberos for Ranger to evaluate real user identities | Dev environment passes username as a plain string |
| Ranger tag sync | Build or buy the OpenMetadata → Ranger tag sync bridge (see hardest problems) | Requires custom Ranger service definition or commercial Cloudera CDP |
| 4-eyes principle | Add an approval step in the Airflow DAG (HumanInTheLoop sensor) before submission ZIP is finalised | Regulatory requirement in several EU jurisdictions — trivial to add |
| Immutable audit log | Stream audit.pipeline_runs to an append-only store (MinIO object lock, or a separate audit database with no UPDATE/DELETE rights) | pg_audit provides database-level immutability; application-level audit table is mutable by admins |
| Secrets management | Replace .env file with HashiCorp Vault or Azure Key Vault; rotate credentials without redeploying | Development convenience; .env is explicitly in .gitignore |
18-Day Retrospective: What the Journey Looked Like
| Days | Phase | Key Output |
|---|---|---|
| 1–4 | Theory foundation | Data governance framework, EU regulatory alphabet, DORA, open-source stack selection |
| 5–7 | Data layer | Synthetic data generation, dbt models (staging→intermediate→mart), column-level lineage |
| 8–9 | Quality + catalog | GX expectation suites, Great Expectations HTML data docs, OpenMetadata with EBA glossary |
| 10 | Security | Apache Ranger RBAC, column masking, row filters, DML restrictions via Trino |
| 11–12 | XBRL generation + validation | Arelle taxonomy parsing, XBRL instance generation, three-pass validation |
| 13 | Orchestration | Full Airflow DAG with 19 tasks, branching on quality/XBRL failure, SLA callbacks |
| 14 | End-to-end lineage | Marquez lineage snapshot, ECB audit query answerer, 5-layer lineage chain |
| 15 | Dashboards | Superset via Trino, 5 virtual datasets, capital + governance audit dashboards |
| 16 | Adversarial testing | 15 pytest tests — bad data, bad roles, broken XBRL, branch routing |
| 17 | Capstone | This post |
| 18 | Production checklist | Tomorrow: what it takes to go from this Docker stack to a real bank deployment |
By the Numbers
| Metric | Value |
|---|---|
| Docker services | 17 |
| Python modules | 8 (ingest, quality, catalog, security, xbrl_gen, xbrl_valid + lineage + audit scripts) |
| dbt models | 13 (5 staging + 4 intermediate + 4 mart) |
| Ranger policies | 10 (4 access-allow, 3 column-mask, 3 row-filter) |
| GX expectation suites | 4 (raw_capital, raw_rwa, raw_liquidity, mart_corep) |
| Airflow tasks | 19 (including 3 quarantine branches) |
| XBRL templates covered | 4 (C 01.00, C 02.00, C 03.00, C 47.00) |
| EBA XBRL concepts mapped | 26 (across all 4 templates) |
| Adversarial test cases | 15 (5 data quality, 7 security, 3 XBRL integrity) |
| Lines of application code | ~2,400 |
| Infrastructure cost | £0 (all open source) |
Why Open Source Is Sufficient for Regulatory Reporting
The most common objection to this stack in the banking industry is: “we can’t use open-source tools for regulatory reporting — we need vendor support.” That objection conflates two different concerns.
Vendor support is a procurement and risk management concern — if Arelle has a bug that generates invalid XBRL, who do you call? The answer is: the EBA’s own XBRL rendering service runs Arelle. Every major European bank uses Arelle for XBRL generation. The EBA itself publishes the taxonomy in Arelle-compatible format. For dbt, the company (dbt Labs) offers enterprise support contracts. For Airflow, Astronomer does. Apache Ranger and OpenMetadata both have commercial distributions (Cloudera CDP, Collibra).
The tools themselves are fit for purpose. What this project demonstrates is that the open-source stack can produce a submission-ready, regulator-auditable XBRL package with full end-to-end lineage, role-based access control, and adversarially-tested governance gates — at zero infrastructure cost. A real bank adds vendor support contracts and production hardening on top of the same architecture. The architecture itself does not change.
Capstone Takeaways
- The Trino-as-gateway pattern is the single most important architecture decision — it makes Ranger enforcement universal and eliminates per-application security logic
- XBRL calculation linkbase integrity is a data modelling constraint, not an output formatting concern — build it into the mart model CTEs from day one
- The Ranger/OpenMetadata tag sync gap is the most significant open-source limitation — bridge it with a CI sync check script until a native integration exists
- Synthetic data must be generated bottom-up from business constraints (capital ratios, LCR thresholds) — not top-down from column definitions
- The six governance pillars (lineage, quality, catalog, security, auditability, regulatory output) are not independent — a control gap in any one pillar undermines the others
- An adversarial test suite that proves controls reject bad input is more valuable to a regulator than a test suite that proves the happy path works
- Every governance control that lives in the application layer can be bypassed by a developer with direct database access — enforce at the data layer (Ranger + pg_audit)
- The end product — a submission ZIP with XBRL instances, validation reports, GX data docs, and a manifest — is what a regulator actually sees: not your pipeline architecture, but the artefacts it produces
Tomorrow, the final blog: Day 18 — the production readiness checklist. What it takes to move from this Docker Compose proof-of-concept to a deployment that a Chief Data Officer would sign off on before a real ECB submission.