

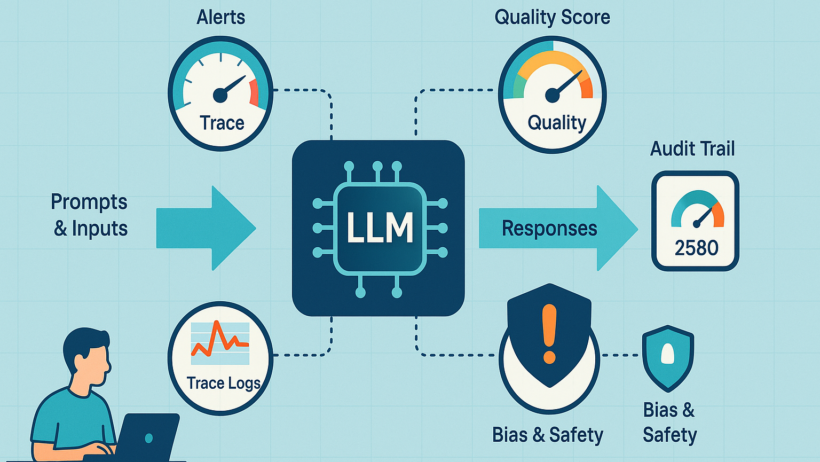
In today’s AI landscape, Large Language Models (LLMs) are powering everything from customer service chatbots to medical diagnostics and autonomous systems. However, their deployment introduces complex risks: harmful outputs, embedded biases, hallucinations, adversarial attacks, and regulatory non-compliance. Securing LLM applications requires a multi-layered approach encompassing technical safeguards, operational rigor, and ethical considerations.
This in-depth blog post explores the critical pillars of LLM security—guardrails, bias mitigation, production safety, human-in-the-loop (HITL) oversight, and emerging governance tools. We’ll examine each through real-world industry examples and, most importantly, from the viewpoint of an LLM Ops Engineer: the role responsible for bridging development and production, ensuring models are scalable, reliable, observable, and safe in live environments.
Drawing from MLOps principles adapted for LLMs (LLMOps), we’ll delve into techniques, tools, challenges, best practices, and implementation details. By the end, you’ll have actionable insights to build more responsible AI systems.
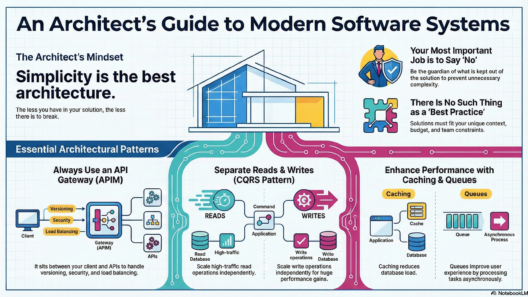
1. Guardrails in LLM Applications
Guardrails are programmable constraints that enforce policies on LLM inputs and outputs, preventing misuse, toxicity, data leakage, or off-topic responses. They form the foundational safety layer in production deployments.
Industry Example: JPMorgan Chase integrates robust guardrails into their internal AI tools and customer-facing chatbots. These systems block prompt injection attacks (e.g., users attempting to extract confidential data via clever phrasing) and filter outputs to comply with financial regulations like those from the SEC, avoiding unauthorized advice or PII exposure.
From an LLM Ops Engineer’s Perspective:
In LLMOps, guardrails are embedded across the inference pipeline—from API gateways to post-processing.
- Input Validation Techniques: Deploy preprocessing at scale using tools like NVIDIA NeMo Guardrails or open-source alternatives (e.g., LLM Guard). Combine regex patterns for known attacks with ML-based detectors (e.g., fine-tuned BERT models for anomaly scoring). In Kubernetes environments, route traffic through service meshes like Istio for centralized validation. Monitor metrics such as input rejection rates (<1% target) and false positives via Prometheus and Grafana dashboards.
- Output Moderation and Filtering: Post-generation, chain multiple checks: keyword/blocklist filtering, toxicity scoring (Perspective API or Hugging Face moderators), and semantic guards (embedding-based similarity to harmful vectors). For low-latency needs, use serverless functions (AWS Lambda) or edge computing (Cloudflare Workers). Implement fallback responses and circuit breakers to halt unsafe generations.
- Advanced Controls: Rate limiting with Redis (token buckets per user/IP), access controls via JWT/OAuth, and dynamic throttling based on system load. Integrate with retrieval-augmented generation (RAG) to ground responses and reduce hallucinations.
Challenges and Best Practices:
- Latency overhead: Optimize to add <200ms; profile with tools like NVIDIA Triton Inference Server.
- Evasion attacks: Conduct regular red-teaming with frameworks like Garak or Promptfoo in staging environments.
- Scalability: Use autoscaling groups and canary deployments for gradual rollout.
- Auditing: Log all guarded interactions in immutable stores (e.g., ELK Stack) for compliance.
Typical guardrails architecture involves layered checks, as shown in these diagrams from industry implementations.
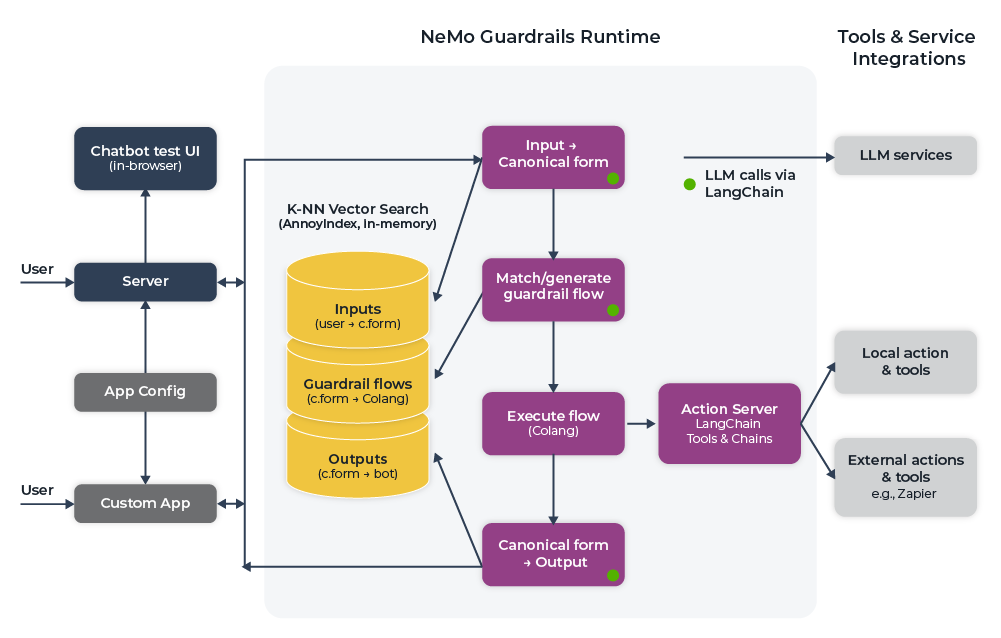
2. Bias Mitigation Techniques
Biases in LLMs arise from imbalanced training data or amplification during fine-tuning, leading to unfair outcomes in areas like hiring, lending, or healthcare.
Industry Example: IBM Watson Health applies comprehensive debiasing in diagnostic and treatment recommendation tools. Techniques like adversarial training help mitigate racial and gender biases inherited from medical datasets, improving equity in predictions and supporting compliance with healthcare fairness standards.
From an LLM Ops Engineer’s Perspective:
Bias mitigation is treated as ongoing model drift monitoring in LLMOps pipelines.
- Data-Centric Approaches: Use automated pipelines (Apache Airflow) for data preprocessing: counterfactual augmentation (e.g., swapping protected attributes like gender/pronouns using NLTK/spaCy), reweighting, or synthetic data generation. Tools like Snorkel enable weak supervision for diverse labeling.
- Model-Level Interventions: During fine-tuning (Hugging Face Trainer), incorporate adversarial debiasing (a discriminator penalizes bias signals) or fairness-aware loss functions. Deploy via shadow testing: Route a portion of traffic to the debiased model and compare.
- Inference-Time Mitigation: Post-processing techniques include calibration, rejection sampling (regenerate until fair), or ensemble methods. Monitor in real-time with libraries like AIF360 or Fairlearn, streaming metrics (e.g., disparate impact <0.8) via Kafka.
- Continuous Auditing: Quarterly full audits with tools like Google’s What-If Tool; integrate user feedback loops for drift detection.
Challenges and Best Practices:
- Trade-offs with performance: Monitor accuracy drops post-debiasing.
- Emerging biases in RAG: Validate retrieved documents for fairness.
- Documentation: Track all mitigations in MLflow for reproducibility and regulatory reporting (e.g., NIST AI RMF alignment).
Flowcharts illustrating bias identification, mitigation strategies, and evaluation processes.
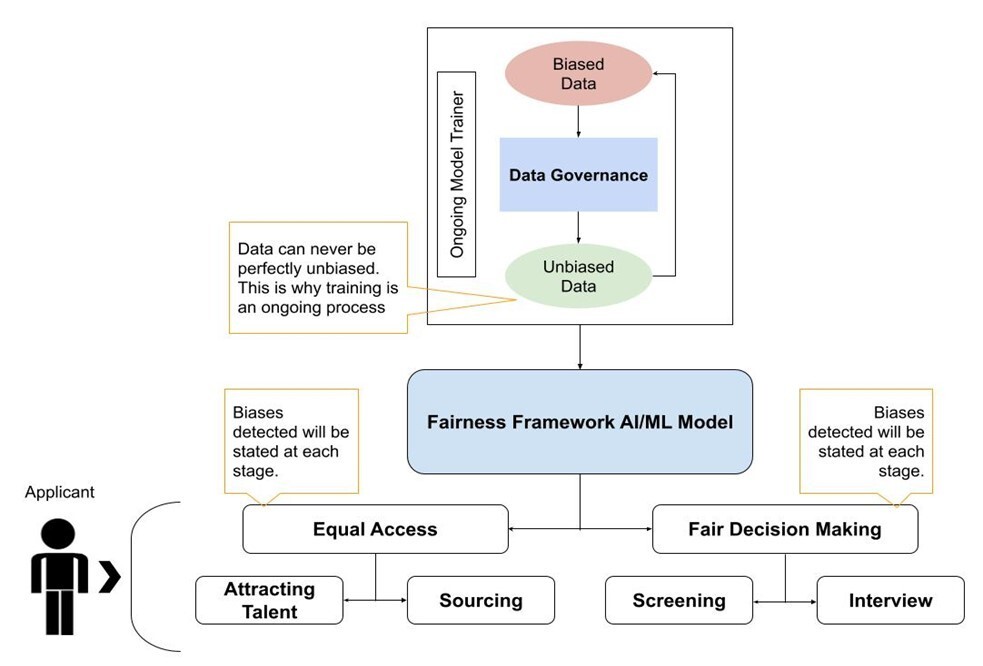
3. Safety in Production
Production safety focuses on resilience: detecting anomalies, handling failures, and maintaining performance under real-world conditions.
Industry Example: Tesla’s Full Self-Driving (FSD) system uses LLM components for natural language command processing and decision explanations. Rigorous monitoring and fallbacks ensure safety, complying with NHTSA guidelines and mitigating risks from hallucinations.
From an LLM Ops Engineer’s Perspective:
- Observability Stack: Full telemetry with Prometheus (metrics like latency, error rates), Jaeger (distributed tracing), and Sentry (exceptions). Detect hallucinations via self-checks or external verifiers.
- Testing and Resilience: Automate adversarial testing (TextAttack) in CI/CD; apply chaos engineering to simulate failures.
- Fallback Mechanisms: Hybrid routing (NGINX proxy) to smaller/safer models or rule-based systems; integrate RAG with vector stores (Pinecone/Weaviate) for fact-grounding.
- Deployment Strategies: Blue-green/canary releases, multi-region high availability.
Challenges and Best Practices:
- Cost vs. safety: Optimize inference with quantization.
- Incident Response: Pre-defined playbooks for breaches.
4. Human-in-the-Loop (HITL) Oversight
HITL integrates human expertise for ambiguous or high-stakes decisions, enhancing accuracy and accountability.
Industry Example: Meta’s content moderation combines LLM flagging with human review for nuanced cases (e.g., cultural context in hate speech), reducing errors and aligning with regulations like the EU Digital Services Act.
From an LLM Ops Engineer’s Perspective:
- Routing Logic: Use orchestration (LangChain/Haystack) with uncertainty measures (e.g., prediction entropy) to escalate.
- Feedback Integration: Tools like LabelStudio for annotations; automate retraining loops.
- Scaling HITL: Async queues (Celery/RabbitMQ), global reviewer pools.
Challenges and Best Practices:
- Cost: Minimize escalations via RLHF over time.
- Latency: Parallel human-AI paths where possible.
5. Emerging Governance Tools
Tools for automated compliance, risk assessment, and auditing are maturing rapidly.
Industry Example: Amazon uses OWASP LLM Top 10-aligned tools in recommendation systems, ensuring GDPR compliance and preventing biased or toxic suggestions.
From an LLM Ops Engineer’s Perspective:
- Key Tools: Calypso AI/HydroX for real-time monitoring; DeepEval for benchmarks; Monitaur/Knostic for policy enforcement.
- Integration: Sidecar containers in Kubernetes; automated reports.
- Frameworks: Align with OWASP, NIST, EU AI Act via scanners in pipelines.
Conclusion: Toward Responsible LLM Deployment
Securing LLMs is an evolving discipline requiring collaboration across teams. As LLM Ops Engineers, we operationalize these concepts to deliver safe, fair, and reliable systems.
Start implementing today: Audit your pipelines, add basic guardrails, and monitor proactively. The responsible AI era demands it.
What aspect of LLM security are you tackling next? Share your thoughts!