

Hello Everyone If you’re knee-deep in building data lakes, warehouses, or pipelines, you’ve probably wrestled with the question: “Which table format should I use?” In the fast-evolving world of data engineering , table formats aren’t just about storing bits they’re about efficiency, scalability, and making your life easier.
In this blog, we’ll break it down step by step. We’ll cover the two main flavors: physical file formats (how data is serialized on disk) and open table formats (the metadata layer that adds smarts like ACID transactions and time travel). I’ll use everyday analogies to make it stick, throw in real-world industry use cases, and share best practices to avoid common pitfalls. By the end, you’ll have a clear playbook for choosing the right one based on your setup.
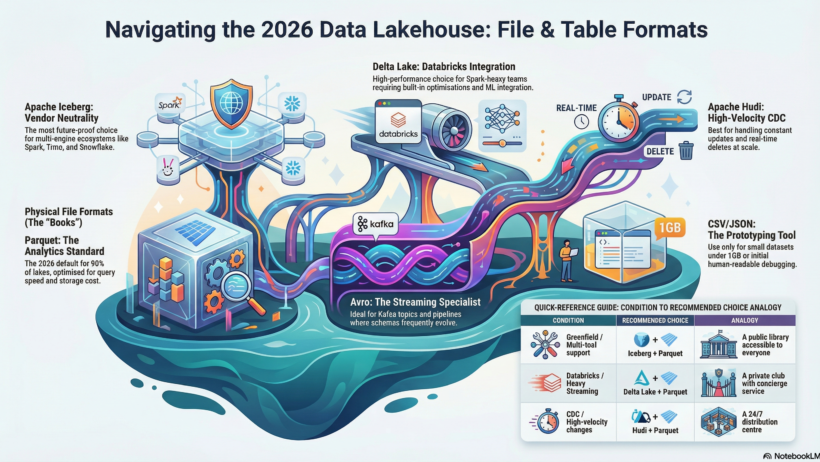
Understanding the Basics: File Formats vs. Table Formats
Think of your data lake as a massive library:
- File formats are the books themselves the paper, binding, and layout that determine how easy it is to read and store.
- Table formats are the library catalog system organizing thousands of books with search, versioning, and checkout rules so multiple people can use it without chaos.
Without a good file format, your reads are slow and wasteful. Without a table format, your “library” is just a pile of books on the floor hard to update, delete, or query efficiently.
Part 1: Choosing Physical File Formats
These are the low-level ways data is stored (e.g., on S3 or HDFS). They’re often used standalone for simple cases or as the foundation for table formats.
Key Options and When to Choose Them
| Format | Analogy | Best For (Conditions) | Industry Use Cases | Best Practices |
|---|---|---|---|---|
| CSV/JSON | Loose sheets of paper or a stack of emails simple but messy for big piles. | Quick prototyping, human-readable data, small datasets, or semi-structured ingestion where schema isn’t fixed. Use when data volume < 1GB and you need easy debugging. | E-commerce logs (e.g., Shopify exports raw order events as JSON for initial ETL). Media companies like Netflix use JSON for event streaming before converting to Parquet. | Always gzip compress; validate schema on read to catch errors early. Avoid for analytics convert to Parquet ASAP for prod. |
| Avro | A flexible notebook with sticky-note schemas evolves without breaking. | Streaming-heavy pipelines with changing schemas (e.g., IoT sensors adding fields). Ideal for Kafka topics or when data must be self-describing. | Ride-sharing apps like Uber serialize ride events in Avro for real-time processing. Healthcare systems use it for patient data streams that evolve with regulations. | Embed schemas in files; use with Snappy compression. Test schema compatibility religiously Avro shines here but fails hard on mismatches. |
| Parquet | An indexed encyclopedia columns grouped for fast skims and compression. | Analytics workloads with large scans, aggregations, or ML features. Choose when query speed and storage cost matter most (e.g., >1TB datasets). | E-commerce giants like Amazon use Parquet in Athena for ad-hoc queries on petabyte-scale logs. Finance firms (e.g., JPMorgan) store trade data for fraud detection models. | Partition wisely (e.g., by date/customer); use Zstd compression for balance. Integrate with Arrow for in-memory speed it’s the 2026 default for 90%+ of lakes. |
| ORC | A compressed Hive-specific binder great for legacy but similar to Parquet. | Hive-dominant environments or when extreme compression is key (e.g., archival data). Pick if you’re stuck in older Hadoop ecosystems. | Telecoms like Verizon use ORC in Hive for billing records analysis. Big retail (Walmart) for inventory logs in legacy clusters. | Enable bloom filters for faster filters; migrate to Parquet if possible ORC is fading but still beats CSV for compression. |
Quick Analogy Recap: If your data is a book, CSV is a handwritten note (easy but fragile), Avro is a editable journal (adaptable), and Parquet/ORC are printed volumes with indexes (efficient for reference).
When to Switch: If you’re ingesting streams, start with Avro/JSON then convert to Parquet for storage. In conditions like high-velocity data (e.g., 1M events/sec), Avro wins for schema evolution; for cost-optimized queries, Parquet crushes it with 10x better compression.
Part 2: Choosing Open Table Formats (Lakehouse Layer)
These build on file formats (usually Parquet) to add database superpowers: ACID upserts, deletes, schema changes, partitioning, and time travel. They’re essential for “lakehouses” where you want warehouse reliability on cheap storage.
Key Options and When to Choose Them
| Format | Analogy | Best For (Conditions) | Industry Use Cases | Best Practices |
|---|---|---|---|---|
| Apache Iceberg | A neutral, high-tech university library app tracks every book version invisibly, works with any “reader” tool. | Multi-engine ecosystems (e.g., mixing Spark, Trino, Snowflake). Choose for large-scale analytics, hidden partitioning, or when avoiding vendor lock-in is key. Ideal for datasets >10TB with frequent schema evo. | Tech platforms like Netflix use Iceberg for content metadata lakes, querying with multiple tools. E-retailers (e.g., Alibaba) for product catalogs with time travel for audits. | Use manifest lists for scale; enable format v2 for deletes. Monitor snapshot expiration to control storage it’s the most future-proof in 2026 with broadest support. |
| Delta Lake | A polished private club library seamless if you’re in the Databricks “family,” with auto-optimizations. | Databricks-centric teams, streaming + ML integrations. Pick for heavy Spark streaming or when you need built-in Z-order and OPTIMIZE. Great for <10TB with real-time needs. | Biotech firms like Pfizer use Delta for clinical trial data pipelines in Databricks. Fintech (Stripe) for transaction logs with ACID merges. | Run OPTIMIZE/VACUUM weekly; leverage Delta Sharing for collaboration. Stick to it if Databricks is your stack perception of bias is real, but perf is top-notch. |
| Apache Hudi | A logistics warehouse with live updates handles constant “deliveries” (upserts) without shutting down. | Streaming CDC, frequent deletes/upserts (e.g., e-com orders changing). Choose for merge-on-read/copy-on-write in high-velocity scenarios. | Ride-hailing like Lyft for driver location updates. Social media (Meta-inspired) for user feed data with real-time merges. | Tune clustering for perf; use Hudi’s incremental pulls for efficiency. Combine with Iceberg if needed Hudi excels in streaming but has more ops overhead. |
Quick Analogy Recap: Iceberg is the open-source standard (like ISBN for books), Delta is the luxury service (fancy but tied to one provider), Hudi is the dynamic warehouse (built for constant flux).
Hybrid Trends in 2026: Some teams use “Hudi on Iceberg” for the best of both. If your condition involves critical sectors (e.g., healthcare needing audits), Iceberg’s time travel is unbeatable.
Part 3: Decision Guide—Which Format in Which Condition?
Here’s where it all comes together. Based on your setup, pick like this:
- Condition: Greenfield project, multi-tool support (Spark + Trino + Athena), focus on neutrality.
Choice: Iceberg + Parquet.
Analogy: Building a public library everyone can access.
Use Case: A startup like a new AI firm building a feature store queries from multiple engines without lock-in.
Best Practice: Start with hidden partitioning to avoid rework; integrate with catalog tools like Nessie for governance. - Condition: Databricks ecosystem, heavy streaming + ML, need auto-optimizations.
Choice: Delta Lake + Parquet.
Analogy: Joining an exclusive club with concierge service.
Use Case: A SaaS company like Slack processing user events in real-time for analytics dashboards.
Best Practice: Use Delta Live Tables for pipelines; monitor compaction to keep file counts low (<1K per table). - Condition: Streaming upserts/deletes at scale, CDC from databases, high-velocity changes.
Choice: Hudi + Parquet (or Avro for ingest).
Analogy: Running a 24/7 distribution center.
Use Case: Banking apps like Revolut handling transaction updates with Debezium CDC.
Best Practice: Choose merge-on-read for read perf; index records for fast lookups scale tests early. - Condition: Legacy Hadoop/Hive, cost-sensitive archival.
Choice: ORC (or migrate to Parquet + Hive metastore).
Analogy: Dusting off an old card catalog.
Use Case: Manufacturing giants like GE storing sensor data in on-prem clusters.
Best Practice: Plan migration to Iceberg; use ACID only if needed legacy often skips it for simplicity. - Condition: Simple prototyping or tiny data.
Choice: CSV/JSON standalone.
Analogy: Scribbling on napkins.
Use Case: Indie devs testing ML models on local datasets.
Best Practice: Convert early; use Pandas for quick loads but enforce schemas.
Overarching Best Practices:
- Test at scale: Benchmark with your workload e.g., Spark jobs on 100GB samples.
- Compression & Partitioning: Always enable (Zstd/Snappy); partition by high-cardinality keys but not too finely (aim <10K partitions).
- Monitoring: Track file sprawl, query perf tools like Databricks Unity Catalog or AWS Glue help.
- Migration Tips: From legacy? Use CTAS in Spark to rewrite to Iceberg. Budget 20% extra time for schema evolution.
- 2026 Trends: Iceberg leads for open-source; Delta for managed. Avoid mixing formats in one lake pick one and standardize.
Wrapping Up: Make It Your Own
Choosing a table format isn’t one-size-fits-all it’s about your conditions: scale, tools, and workload. Start with analogies to intuition-check, then validate with POCs. In 2026, lakehouses are maturing, so lean toward open formats like Iceberg for longevity.